Leverage the power of AI to optimize, analyze, and visualize your SQL code - all seamlessly integrated within SQL Server Management Studio
Get instant answers to your SQL questions with our context-aware AI chat
A code review tool that effortlessly identifies issues and recommends optimal solutions
Condense complex code into clear, concise summaries
Visually map out your business logic and export for reference
Sensitive information redacted prior to request submission
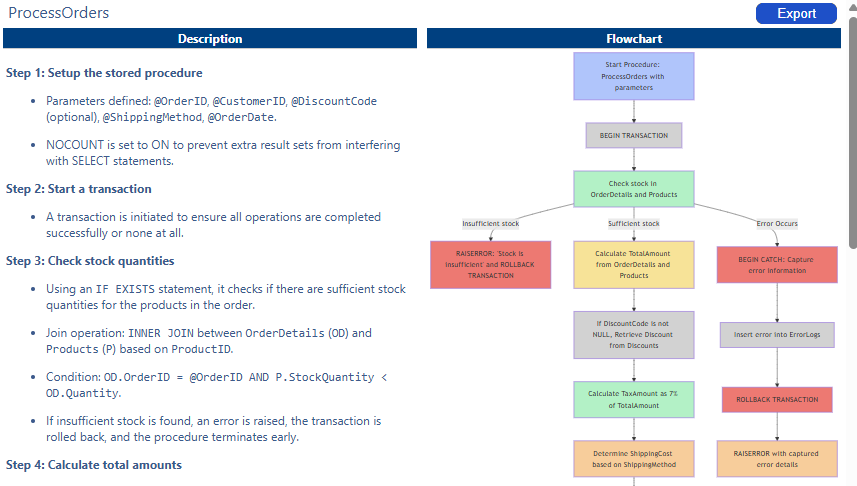
Transform complex SQL code into intuitive, interactive flowcharts. Gain better understanding of your database logic.
Your data's security is our top priority. SQL Copilot employs advanced techniques to ensure your sensitive information remains protected.
Join a growing community of developers using SQL Copilot to write better, faster, and more efficient SQL code.